ClickHouse 数据压缩与解压
ClickHouse 是一款真正面向列的DBMS,就是一款列式数据库,所以ClickHouse非常适合作为OLAP的数据查询引擎。通常列式数据库具有非常好的数据压缩效果,因为每列数据的数据类型一致,保存时会作为一个数组数据挨着保存,这样压缩算法具有非常好的压缩效果,在OLAP查询场景下可以有效的提高整个系统的吞吐量。
ClickHouse目前支持的数据压缩算法是lz4和zstd,其中zstd是实验性,默认情况下ClickHouse采用的是lz4压缩算法。压缩的主要配置项示例如下,通常情况下不会去更改这几个配置项,因为默认配置就可以让数据压缩效率非常高。
1 | <compression incl="clickhouse_compression"> |
关于压缩算法的测试,见这篇文章。简而言之,LZ4在速度上会更快,但是压缩率较低,ZSTD正好相反。尽管ZSTD比LZ4慢,但是相比传统的压缩方式Zlib,无论是在压缩效率还是速度上,都可以作为Zlib的替代品。
压缩比
官方有提供星型模块基准测试的案例,clickhouse-in-a-general-analytical-workload-based-on-star-schema-benchmark 该基准测试案例lineorder数据表字段基本都是整形,该表lineorder原始数据有150亿条记录,原始数据总大小为1.7TB,导入到ClickHouse后lineorder数据表占用464GB,压缩比达到了3.7倍数。
目前我们的ClickHouse数据库中存储一些nginx原始日志信息raw_cdn_nginx_log_all,nginx原始访问日志以及维度扩展之后的日志数据每行大概会有100左右个字段信息,我们截取其中40多个有助于OLAP查询高频字段,数据表字段信息:
1 | ( |
ClickHouse集群有4台机器,2019-06-14这一天集群的数据记录条数是2.4亿,那时候还不算业务爆发期,这2.4亿条的数据在clickhouse集群中总占用大小在12G左右,每台机器占用空间大小为3G左右。
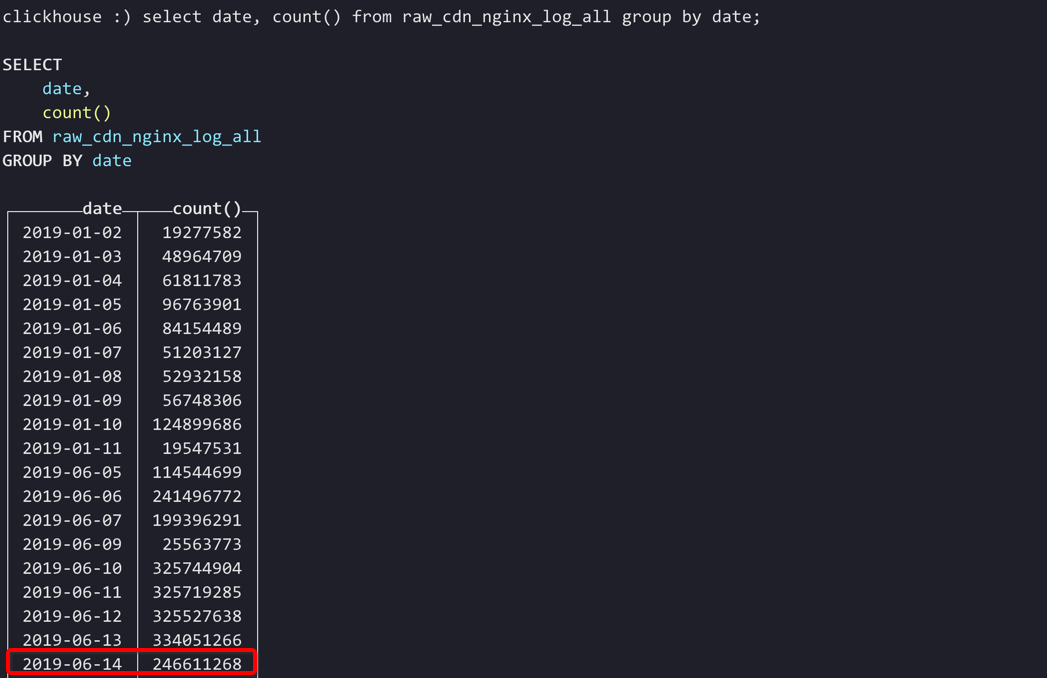
每行原始数据信息大概如下,每条JSON格式的数据记录大概是1000字节左右,2.4亿条JSON格式的输入数据大小为240G左右。如果是以CSV格式存储,则单条记录大小大概是380字节,2.4亿条CSV格式的输入数据大小为93G。
1 | {"timeStamp":"2019-06-14 02:37:31","date":"2019-06-14","province":"GZ","isp":"CM","upstream_addr":"","hostname":"SR-CNCM-GZKWE-38-23","machineIP":"xxx","country":"CN","scheme":"https","upstream_local_port":"","channel":"xxx","node":"IDC-CNCM-GZKWE-Dnion","cacheGroup":"SG-CNCM-GZKWE-cacheOpt-01","city":"KWE","view":"CN_CM_XN_GZ","status":"200","customer":"meitu","nodeisp":"CM","app":"APP-WEB","http_host":"api.meipai.com","upstream_status":"200","deviceID":"9233d8bbfe37eed97679b6f768858d06","remote_addr":"223.104.96.19","request_id":"31f80ef11dc338493cf25c5334dcbfc8","serviceGroupId":"1152","request":"","http_referer":"","serverType":"0","conn_state":"","upstream_keepalive":"1","http_user_agent":"","body_bytes_sent":"8069","client_rtt":0.029,"ssl_handshake_time":0,"response_time":0.259,"first_byte_time":-0,"upstream_response_time":"0.258","bytes_sent":"8364","download_time":-0,"half_rtt_time":2685.709,"request_time":0.259} |
总结:2.4亿条原始nginx日志,原始JSON格式数据大小240G,CSV格式的数据大小为93G,存储到ClickHouse后占用磁盘大小12G左右。不管以哪种方式存储,ClickHouse具体非常好的数据压缩比。目前线上是从kafka消费JSON格式数据入库到ClickHouse。如果数据表字段少一点或者是数据都存储在一台机器上,ClickHouse压缩比会更高。ClickHouse数据压缩这篇文章有测试过1亿条数据记录ES存储磁盘占用33GB,ClickHouse磁盘占用1.4GB。
ClickHouse解压缩
当我们在查询ClickHouse数据库数据时,如果采用perf工具对ClickHouse进程采样,会发现LZ_decompress_fast方法占用的CPU时间最多。
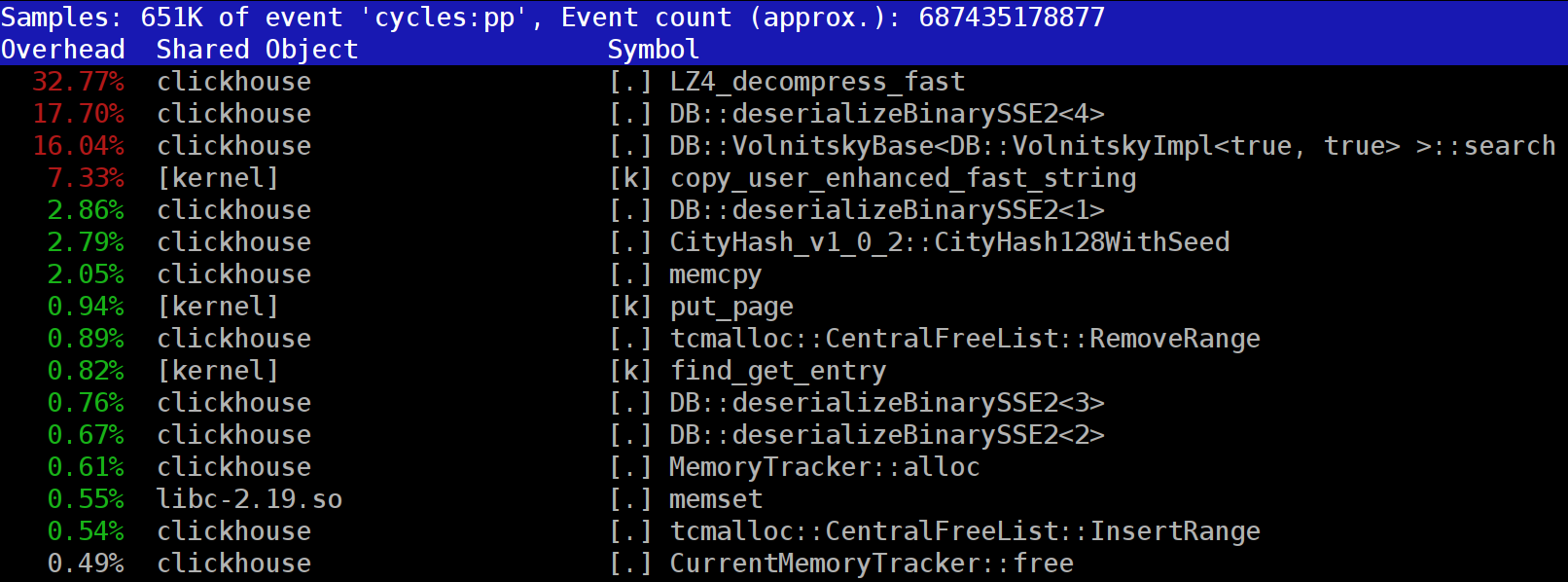
ClickHouse数据以压缩的形式存储在本地磁盘中,当数据查询时ClickHouse为了减少CPU使用资源会尽量少做一些事情。在许多情况下,所有潜在的耗时计算都已经得到了很好的优化,而且用户编写了一个经过深思熟虑的查询,那么剩下要做的就是执行解压缩。
那么为什么LZ4解压缩成为一个瓶颈呢?LZ4看起来是一种非常轻的算法:数据解压缩速率通常是每个处理器内核1到3 GB/s,具体取决于数据。这比典型的磁盘子系统快得多。此外,我们使用所有可用的中央处理器内核,解压缩在所有物理内核之间线性扩展。
首先,如果数据压缩率很高,则磁盘上数据占用空间就很小,在读取数据时磁盘IO会比较低,但是如果待解压的数据量很大则会影响到CPU使用率。在LZ4的情况下,解压缩数据所需的工作量几乎与解压缩数据本身的量成正比;其次,如果数据被缓存,你可能根本不需要从磁盘读取数据。可以依赖页面缓存或使用自己的缓存。缓存在面向列的数据库中更有效,因为只有经常使用的列保留在缓存中。这就是为什么LZ4经常成为CPU负载的瓶颈。
在官方的这篇博客中How to speed up LZ4 decompression in ClickHouse,作者反馈有人希望ClickHoouse不要以数据压缩的方式存储数据,因为反馈者认为数据查询时是因为数据解压拖慢了整个查询进度,并且这个人还在github上提了一个PR,最后维护者觉得Ok. If you are not going to use this compression method, it's not worth to implement.。
如果可以使用缓存,为何ClickHouse不把解压后的数据存在缓存中呢,这样可以减少很多数据解压的场景,ClickHouse也提供了cache配置项the cache of decompressed blocks。在博客中作者认为这种方式对内存是极大的浪费,并且只有在查询数据量很小的场景下是有用的。我个人也觉得如果缓存住解压后的数据,ClickHouse进程肯定会经常发生OOM。ClickHouse高效的数据压缩设计其实是一个很好的设计方案,首先可以减小磁盘的数据占用;其次在shard的replica副本个数超过1时,replica之间的数据同步也可以更高效。
目前在生产环境中,ClickHouse简单数据查询P99的时间还是在秒级返回,只有在复杂的数据查询场景下查询时间会增加到几秒,例如多个表join,其实在这个场景下更多的做法应该是优化SQL查询语句,尽量避免大量表join查询。
How to speed up LZ4 decompression in ClickHouse这篇官方博客中作者还提到了LZ4是如何工作的以及数据解压缩的优化手段。