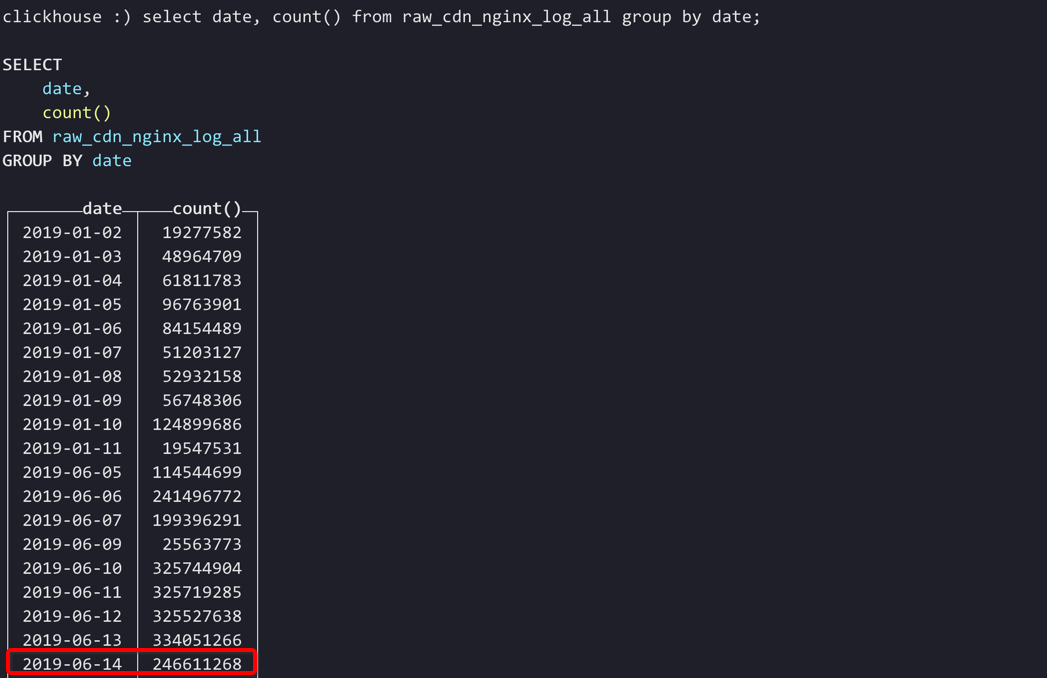
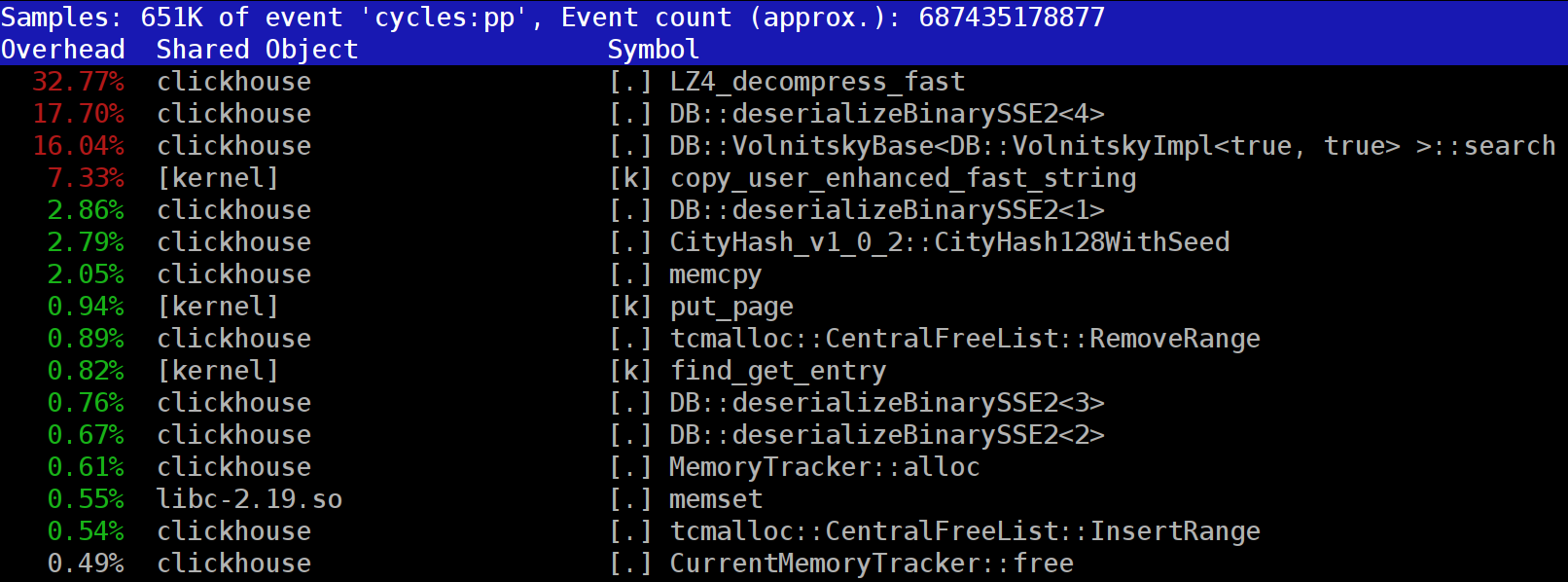
在官方的这篇博客中How to speed up LZ4 decompression in ClickHouse,作者反馈有人希望ClickHoouse不要以数据压缩的方式存储数据,因为反馈者认为数据查询时是因为数据解压拖慢了整个查询进度,并且这个人还在github上提了一个PR,最后维护者觉得Ok. If you are not going to use this compression method, it's not worth to implement.。
如果可以使用缓存,为何ClickHouse不把解压后的数据存在缓存中呢,这样可以减少很多数据解压的场景,ClickHouse也提供了cache配置项the cache of decompressed blocks。在博客中作者认为这种方式对内存是极大的浪费,并且只有在查询数据量很小的场景下是有用的。我个人也觉得如果缓存住解压后的数据,ClickHouse进程肯定会经常发生OOM。ClickHouse高效的数据压缩设计其实是一个很好的设计方案,首先可以减小磁盘的数据占用;其次在shard的replica副本个数超过1时,replica之间的数据同步也可以更高效。
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=30000 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=10
maxClientCnxns=2000
maxSessionTimeout=60000000 # the directory where the snapshot is stored. dataDir=/opt/zookeeper/{{ cluster['name'] }}/data # Place the dataLogDir to a separate physical disc for better performance dataLogDir=/opt/zookeeper/{{ cluster['name'] }}/logs
# To avoid seeks ZooKeeper allocates space in the transaction log file in # blocks of preAllocSize kilobytes. The default block size is 64M. One reason # for changing the size of the blocks is to reduce the block size if snapshots # are taken more often. (Also, see snapCount). preAllocSize=131072
# Clients can submit requests faster than ZooKeeper can process them, # especially if there are a lot of clients. To prevent ZooKeeper from running # out of memory due to queued requests, ZooKeeper will throttle clients so that # there is no more than globalOutstandingLimit outstanding requests in the # system. The default limit is 1,000.ZooKeeper logs transactions to a # transaction log. After snapCount transactions are written to a log file a # snapshot is started and a new transaction log file is started. The default # snapCount is 10,000. snapCount=3000000
# If this option is defined, requests will be will logged to a trace file named # traceFile.year.month.day. #traceFile=
# Leader accepts client connections. Default value is "yes". The leader machine # coordinates updates. For higher update throughput at thes slight expense of # read throughput the leader can be configured to not accept clients and focus # on coordination. leaderServes=yes
# TODO this is really ugly # How to find out, which jars are needed? # seems, that log4j requires the log4j.properties file to be in the classpath CLASSPATH="$ZOOCFGDIR:/usr/build/classes:/usr/build/lib/*.jar:/usr/share/zookeeper/zookeeper-3.5.1-metrika.jar:/usr/share/zookeeper/slf4j-log4j12-1.7.5.jar:/usr/share/zookeeper/slf4j-api-1.7.5.jar:/usr/share/zookeeper/servlet-api-2.5-20081211.jar:/usr/share/zookeeper/netty-3.7.0.Final.jar:/usr/share/zookeeper/log4j-1.2.16.jar:/usr/share/zookeeper/jline-2.11.jar:/usr/share/zookeeper/jetty-util-6.1.26.jar:/usr/share/zookeeper/jetty-6.1.26.jar:/usr/share/zookeeper/javacc.jar:/usr/share/zookeeper/jackson-mapper-asl-1.9.11.jar:/usr/share/zookeeper/jackson-core-asl-1.9.11.jar:/usr/share/zookeeper/commons-cli-1.2.jar:/usr/src/java/lib/*.jar:/usr/etc/zookeeper"